

ML Testing Refresher
Why Testing ML Feels Like Geology, Not Geometry

Table of Contents
TL;DR
Testing machine learning (ML) systems fundamentally differs from testing traditional code. It requires a multilayered approach that tests three artefacts: code, data, and models. Classic tests, such as unit and integration tests, are combined with specialised data, model, and end-to-end infrastructure tests. Performance metrics alone are insufficient; complementary tests are required. Each ML paradigm (supervised, unsupervised, and reinforcement learning) also needs distinct testing objectives and evaluation techniques.

Testing ML systems is hard due to their complexity across multiple dimensions—code, data, and models. Traditional testing methods, such as unit tests, integration tests, acceptance tests, system tests (functional and non-functional), regression tests, and practices like test-driven development (TDD), may feel tedious, but they provide a valuable, repeatable framework ensuring software correctness. In contrast, ML model testing primarily delivers performance statistics, which can sometimes feel ambiguous. What does 91% accuracy genuinely mean in practice?
Why ML System Testing is Different: The Skyscraper vs. Rock Face Analogy
Let's consider a visual analogy to put things into perspective: Imagine testing a glass skyscraper versus a fissured rock face. The skyscraper surface can be confidently verified with precise measurements and well-understood engineering principles. A handful of targeted tests are sufficient to justify your confidence. In contrast, a rock face is far more complex. Composed of possibly igneous, sedimentary, and metamorphic layers shaped by processes like sedimentation, pressure, erosion, heating, and cooling, its surface is inherently irregular and unpredictable. While you can take samples and apply statistical extrapolations, each measurement offers only an approximation, never absolute certainty. ML testing is much like the rock face.

Traditional software behaves predictably; the same input always yields the same output. ML systems, on the other hand, learn patterns from ever-changing data, creating opaque decision boundaries. A traditional software failure is typically straightforward: a button isn't clickable, or a form doesn't submit. Such deterministic logic makes debugging clear-cut. Conversely, an ML system's slight input variations (tiny perturbations) can trigger significantly different outputs or flip predictions. Let’s take a look at the comparison testing workflow for traditional software and ML systems below:
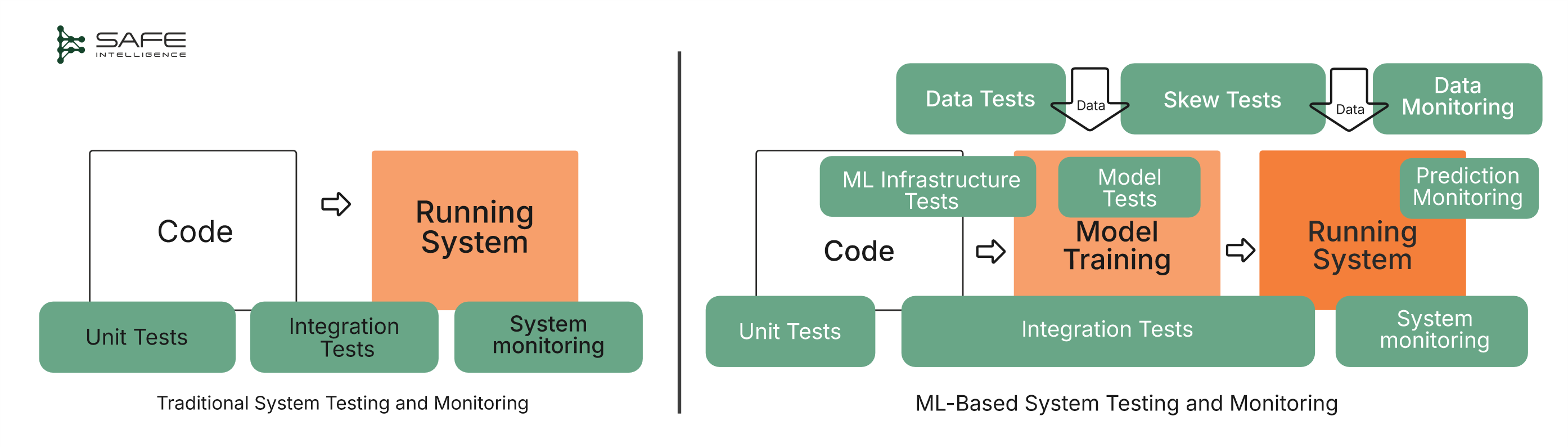
Here’s a comprehensive overview that clearly differentiates the types of testing:
The real cost of machine learning failures extends far beyond mere technical glitches, manifesting as significant financial losses, reputational damage, and even safety hazards. Consider the recent Zoox Robotaxi recalls, which highlighted the critical need for comprehensive testing; a crash in San Francisco revealed that insufficient pedestrian-detection tests forecasts forced Amazon's robotaxi unit to recall over 270 vehicles. Similarly, consider Zillow's iBuying collapse, where its ML models consistently overestimated home prices, resulting in a $420 million loss and the entire program being shut down. These examples underscore that rigorous, multifaceted testing is a good practice and an indispensable safeguard against catastrophic operational and financial repercussions.

A Deeper Look into ML Model Testing
Ensuring that ML models behave as intended—consistent and stable—is crucial, especially when they power critical real-world applications. A model's behaviour can vary significantly based on code, data quality, model architecture, training procedures, production environments, and even adversarial scenarios. The primary goal of ML system testing is to build confidence that the model will function correctly, robustly, and predictably under diverse, uncertain, and complex real-world conditions.
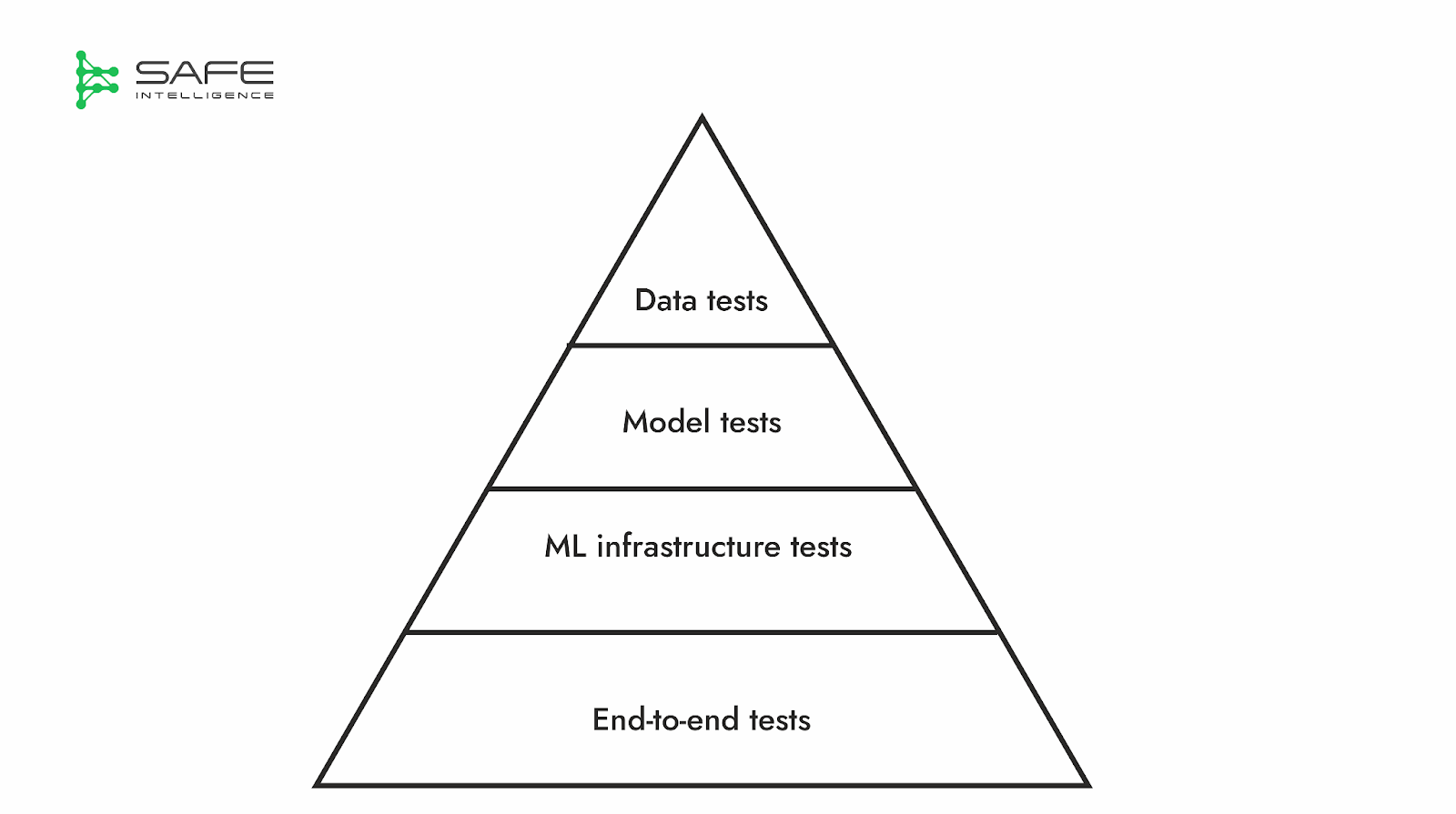
It is best practice to employ a multi-layered approach to thoroughly test our ML systems, which often includes:
Data tests, which include, but are not limited to, schema validation, data quality assessments, statistical distribution checks, and outlier and drift detection.
Model testing spans two critical dimensions: performance and behaviour. Performance testing evaluates how effectively a model meets its objectives through quantitative metrics and standard benchmarks, assessing its generalisation capabilities and detecting overfitting or underfitting. Behaviour testing shifts towards qualitative, scenario-driven assessments, examining how the model operates under challenging or specific conditions. This includes evaluating robustness to noise and adversarial attacks, interpretability (local and global explanations), compliance with safety constraints, and fairness measures like demographic parity and equal opportunity.
ML infrastructure and end-to-end testing are crucial for operationalising ML systems. These tests span the entire MLOps lifecycle, including rigorous CI/CD pipeline checks, validating data integrity via feature store assertions, verifying the functionality of model registry and serving endpoints, establishing robust rollback mechanisms, configuring appropriate monitoring and alerting thresholds, and ensuring the correct execution of various deployment strategies.
ML Model Testing Across ML Paradigms
Just as different geological formations would require different assessment techniques, model testing's specifics for performance and behaviour must adapt to the model's learning approach, or its underlying paradigm. The three primary ML paradigms—supervised, unsupervised, and reinforcement learning—each have their difficulties and necessitate distinct testing approaches. Here's a table summarising the primary ML paradigms and their corresponding test objectives:
You can read more about these paradigms on the Wolfram blog, but here’s a quick overview is as follows:
Supervised Learning
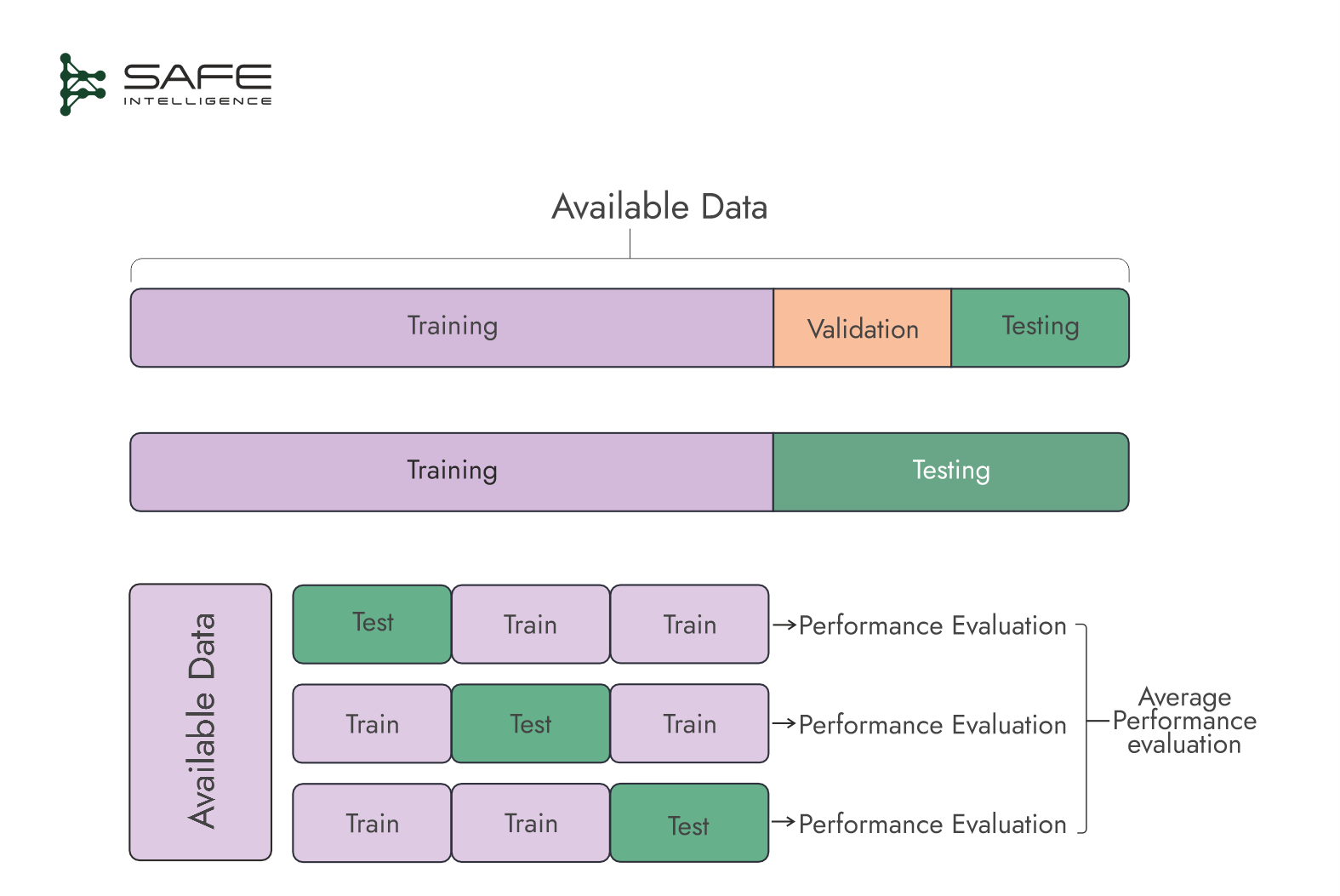
Supervised learning is characterised by labelled input/output pairs; the main goal is to build a model that generalises well to unseen data. A good approach to testing is splitting the data into a training set, a validation set, and a test set. The training set is used to train the model, the validation set is used for hyperparameter tuning and model selection, and the test set is reserved for the final offline evaluation. Common splits include 70:15:15 (train:validation:test) or 70:30 (train:test). Cross-validation is a common technique that minimises the loss of training data for the validation set while still ensuring a rich test set by iteratively training and validating different subsets (folds).
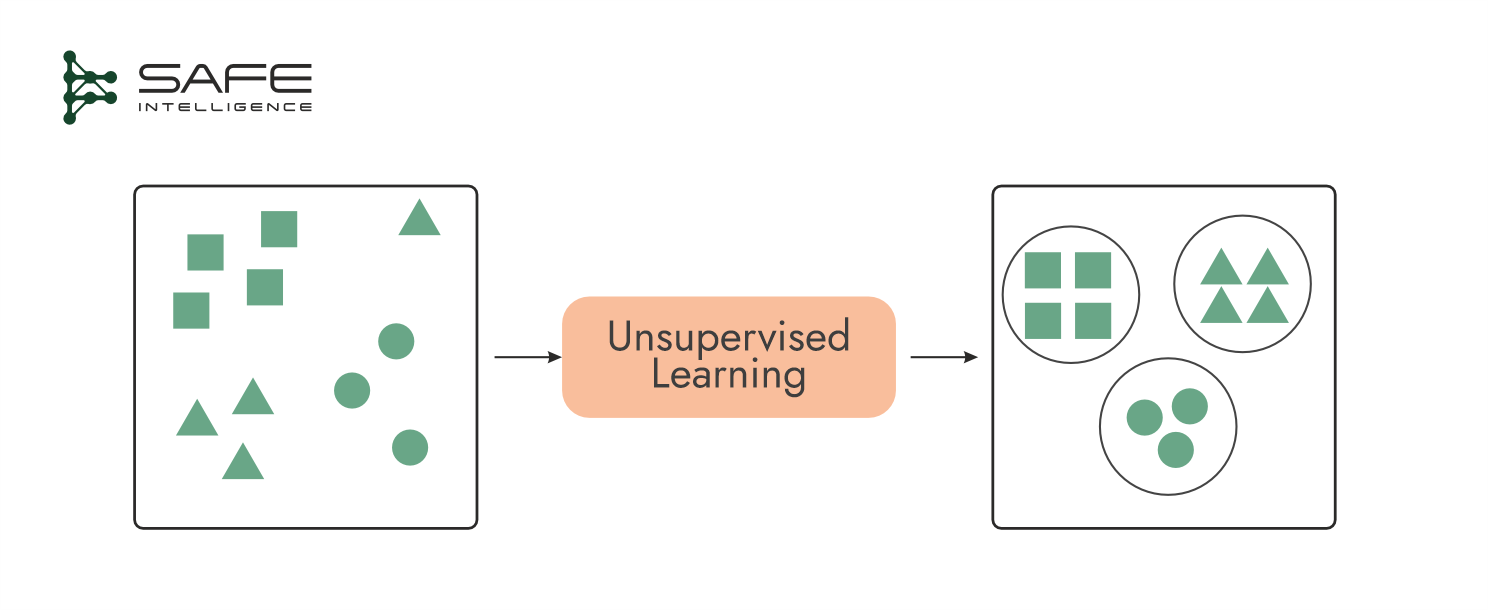
Unsupervised Learning
Unsupervised learning aims to discover hidden patterns or groupings without labelled outputs, so there are no explicit splits of the dataset like we see in supervised learning. Instead, it makes use of intrinsic evaluation for clustering (like the silhouette coefficient, Davies-Bouldin index, inertia, the sum of squared distances, and the Calinski-Harabasz index) and dimensionality reduction (like reconstruction error and explained variance ratio). Additionally, it incorporates extrinsic evaluation methods, such as visualisations and domain expert evaluations, which are critical due to the lack of ground truth.
Reinforcement Learning
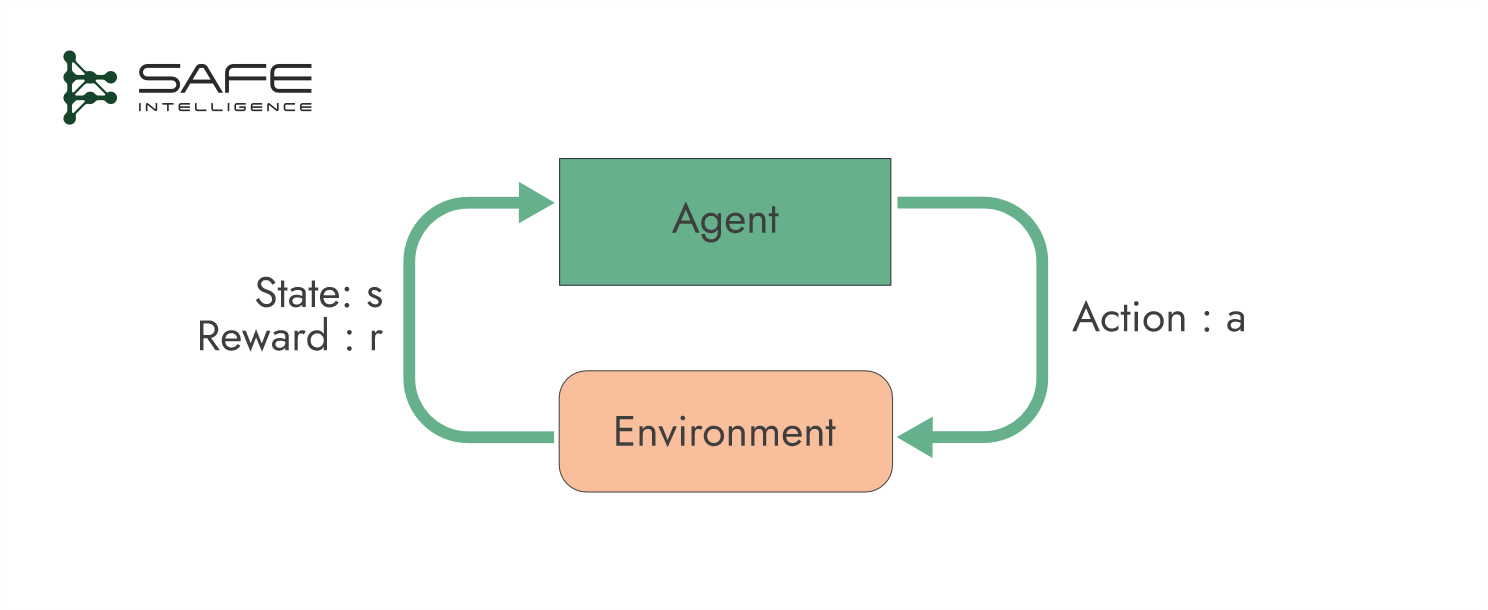
Lastly, in reinforcement learning, an agent interacts with an environment and learns a policy (a decision-making strategy) through repeated trials, aiming to maximise cumulative rewards and minimise penalties (negative rewards). Testing involves evaluating the learnt or trained policy in another controlled environment or set of episodes.
Key Takeaways
Without systematic tests, we have no insight into how a model behaves. Yet the tests we can run look different from classic software checks: they rely on statistical sampling and extrapolation rather than a tiny set of fully representative inputs. We're only just getting started with this series, but already, we're getting a hint that building ML systems and testing whether they will function well in the real world is a big challenge. This article offers a few key takeaways:
Ultimately, effective testing supports ML systems' safe, effective, and responsible deployment. This is crucial for avoiding costly failures and building user trust.
Different types of testing are essential, from data and model tests to infrastructure and end-to-end tests, ensuring comprehensive coverage of the ML system's components.
ML model testing involves a blend of quantitative and qualitative model assessment. This means going beyond accuracy scores to understand model behaviour, such as robustness and explainability in real-world scenarios.
We've seen how testing strategies vary for the respective ML paradigms (supervised, unsupervised, and reinforcement learning), each demanding specific objectives and evaluation techniques.
The need for rigorous and continuous testing is paramount. Failure in ML is expensive; real-world incidents prove that weak tests translate directly into significant financial loss, reputational damage, and even safety hazards.
COMING UP… In the next article of this series, we'll explore how ML validation begins with test design.
Resources & Further Reading
For further reading, see the links below, which are some of the best blog posts on testing for machine learning.
Google: The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
Made With ML by Anyscale: Testing Machine Learning Systems: Code, Data and Models
Neptune AI: Automated Testing in Machine Learning Projects [ABest Practices for MLOps]
CS188 Artificial Intelligence, Fall 2013. Lecture 10: Reinforcement Learning