

ML Benchmarking Primer
Measure, Compare, and Improve Your ML Systems

Table of Contents
TL;DR
In the previous article of this series, we explored how to design effective test sets to get the best out of our validation exercise. But once you've nailed validation, the next big question is: How well does your model perform compared to other approaches or experiments? That's exactly where machine learning benchmarking comes into play. So, is this a feel-good exercise? Does it making you feel inadequate, or is it a useful tool? We will cover how to think of ML benchmarking as layers, cover choices between public and private benchmarking, and present a clear systematic workflow to connect technical model performance directly to measurable business impact. Without benchmarks, every experiment run thinks it’s the valedictorian.

On October 14, 1947, test pilot Chuck Yeager pushed his plane through the “sound barrier”, a limit many believed was fatal. His flight didn’t just produce a sonic boom; it shattered the assumptions of an entire field, proving that what seemed impossible was merely the next frontier. In computing, benchmarks are our sound barriers. They are the standard measures that motivate change, drive breakthroughs, and push researchers to exceed perceived limits. While your next developed model might not produce a sonic boom, it faces its own set of critical barriers. (Also, if you’re working on breaking the lightspeed barrier, let us know we’d like to invest!)

The previous article in the series gave us a foundation for model evaluation by designing test sets. Tests by themselves though are not anchored to anything. Benchmarking builds on tests by comparing multiple viable models. This comparison helps identify the best balance of performance, cost, latency, and risk for a specific business objective. Benchmarking can take time and be laborious but there are a lot of benefits. Let’s get started…
Why Benchmarking Matters
Benchmarking isn't about promoting one approach over another but objectively measuring and guiding requirements across any model deployment scenario. It fulfills four essential roles:
Objectively compare solutions: Benchmarks level the playing field. Rigorous benchmarks applied uniformly to models, infrastructure, and data methods cut through the marketing hype, internal biases, and subjective debates to deliver impartial rankings. However, as “Lies, Damned Lies, and Benchmarks” explains, public benchmarks can be gamed, as tweaking enough variables almost always yields a number that supports an argument, enabling deception and abuse.
Make Confident Trade-Off Decisions: Benchmarks provide clear success criteria, but rarely does one solution outperform others on every front. Instead, they reveal trade-offs. One model may offer higher accuracy but increase latency, while another cuts costs but struggles with out-of-distribution data. Teams can confidently choose the solution that best fits their operational needs using a multi-metric decision framework, such as a weighted scorecard.
Measure and Track Progress: Benchmarking isn't a single, isolated event. Regular, systematic benchmarking establishes historical performance records that help teams:
Quantify incremental improvements.
Quickly identify performance regressions.
Demonstrate tangible ROI over time.
Consistent benchmarking creates an evidence-backed narrative of continual improvement.
Raise the Bar and Advance the Field: Effective benchmarks set ambitious, motivating targets, pushing teams to innovate continuously. Much like Yeager's aviation milestone, benchmarking sets clear goals that inspire teams to explore beyond established limits, driving continuous improvement and field-wide advancement.
Organisations consistently apply benchmarks to ensure their machine learning solutions reliably deliver measurable value, regardless of the underlying technology trends.
What Counts as a "Benchmark"?
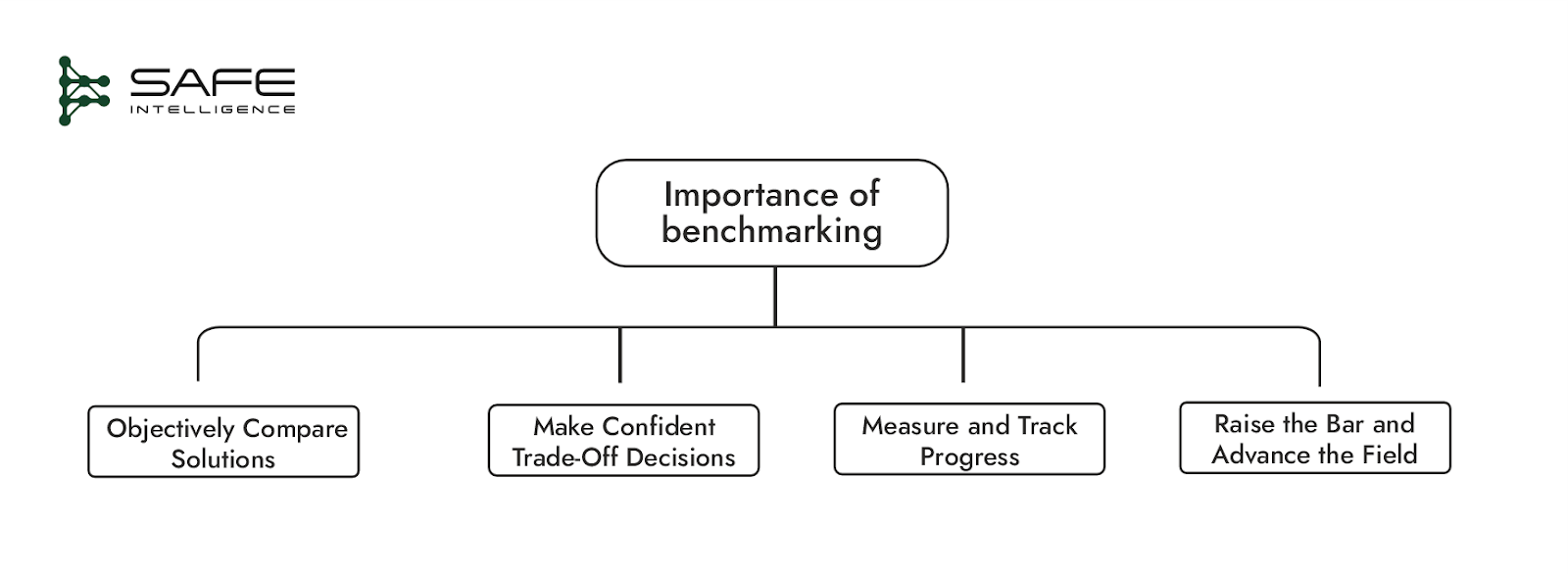
A benchmark is a controlled experiment applied to any layer of the ML stack. To isolate the impact of a change, you must hold other variables constant. Benchmarking in ML isn’t a monolithic activity but a practice that can be broken down into three primary layers: infrastructure/system benchmarks, model benchmarks and data benchmarks.
Infrastructure/System Benchmarks
Goal: Identify the infrastructure (hardware and software) configuration that delivers reliable, scalable, and efficient model balancing performance, latency, throughput, cost, and energy use.
Freeze: Model, dataset
Vary: Hardware accelerators, precision modes (FP32 vs INT8), compiler optimization, deployment architectures, network topology for distributed training
Metrics: Throughput (queries/sec), latency (p95/p99), cost per inference, energy use, CO₂ emissions
Established Suites: MLPerf Training & Inference
Real-world Example: Your baseline is a ResNet-50 model on NVIDIA V100 GPUs with 80 ms latency at $0.001 per inference. Benchmarking shows that migrating to H100 GPUs with INT8 precision reduces latency to 12 ms and cost to $0.0005 per inference, clearly justifying the upgrade.
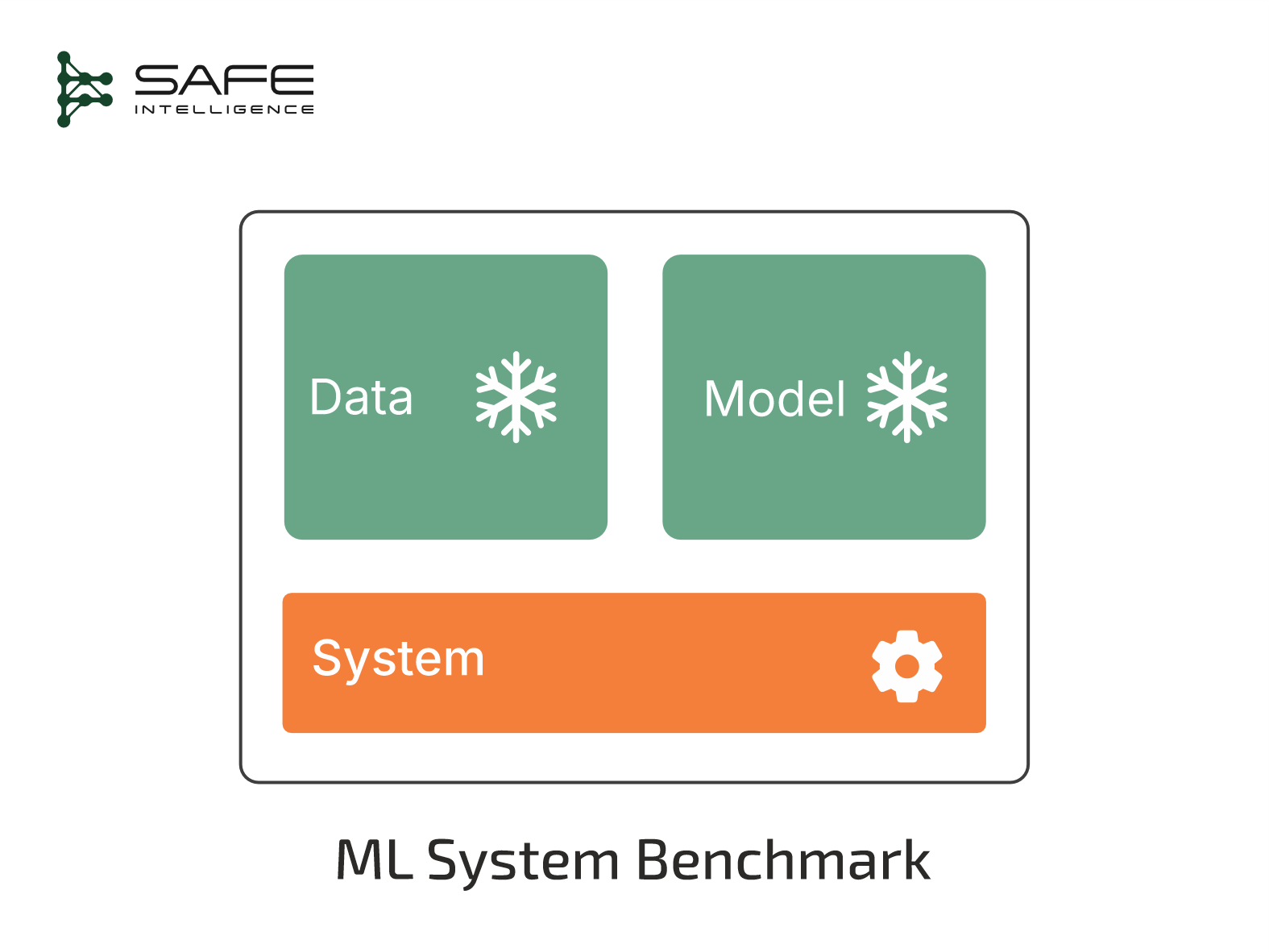
Model Benchmarks
Goal: Determine the model architecture and training strategy that maximises predictive power and aligns with business and ethical requirements. Model benchmarks are the traditional and most common type of benchmarks.
Freeze: Dataset, system (infrastructure, including evaluation metrics)
Vary: Model architectures, hyperparameters, feature engineering, and optimisation methods.
Metrics: Accuracy, ROC-AUC, mAP, BLEU, risk, and operational readiness (covering robustness, explainability, fairness and bias)
Public Yardsticks: ImageNet , CIFAR-10, GLUE, Kaggle/Zindi competitions
Real-world Example: A random forest baseline yields an AUC of 0.81 for churn prediction. A benchmark study reveals that a well-tuned LightGBM model lifts AUC to 0.87, surpassing both the baseline and the operational
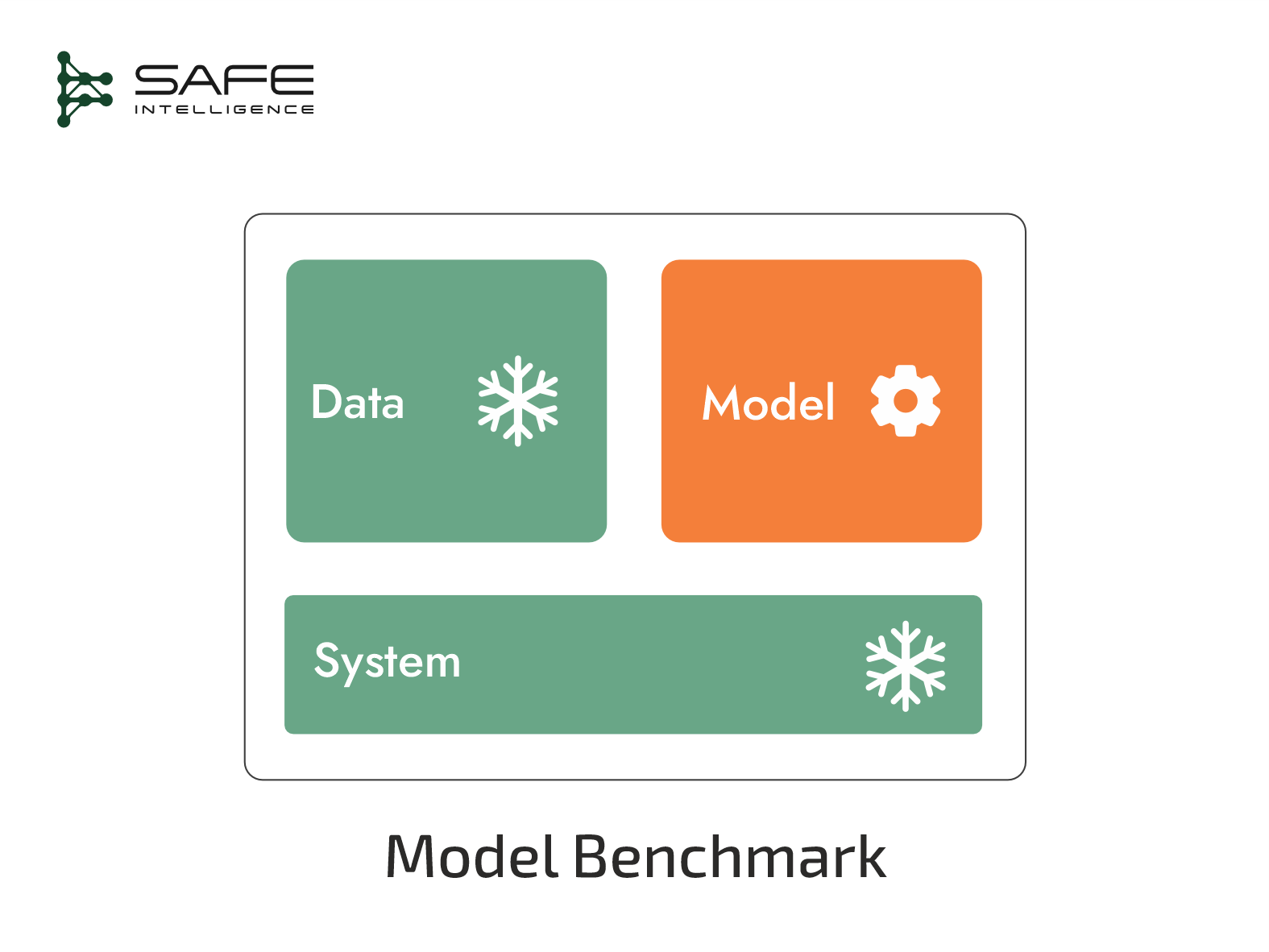
Data Benchmarks
Goal: Evaluate the ROI of data-centric strategies, quantifying how changes in data directly translate to model performance.
Freeze: Model, system (infrastructure including evaluation metrics)
Vary: Data volume, sampling strategies, annotation quality, synthetic data augmentation, data selection/valuation strategies.
Metrics: Minority-class precision/recall, out-of-distribution robustness, performance uplift per dollar spent on data.
Notable Suites: DataPerf
Real-world Example: You have an image classification model with 75% accuracy. One benchmark evaluates the ROI of adding 50,000 synthetic images, which raises accuracy to 82%. Another evaluates the impact of spending the same budget on expert re-labelling of the 10,000 most-confused examples, which lifts accuracy to 85%. This data-centric benchmark provides a clear path for resource allocation.
Building or Choosing Your Benchmarks
A benchmark’s value is not in the numbers it produces but in the decisions it enables. Before any experiments are run, the first decision is whether to adopt a public standard or develop a private, internal benchmark. This choice dictates your point of comparison: the broader industry or your own unique business context. Most mature organisations use a hybrid approach, but understanding the trade-offs is key.
Once you’ve chosen your approach, define success with metrics that map directly to business impact. Use a portfolio of measures to capture trade-offs and ensure real-world relevance. With strategy and metrics set, focus on execution: rigorous benchmarking should be reproducible, objective, and decision-driven. Below is a practical workflow to guide each benchmarking run from hypothesis to actionable insight.
Formulate a Falsifiable Hypothesis: Start with a precise, testable question linked to business KPIs. Replacing our baseline logistic regression model with an XGBoost ensemble will lift ROC-AUC from 0.78 to 0.85, keep median inference latency below 10ms, and is projected to boost monthly revenue by £35k through a 12% reduction in false negatives.
Design the Reproducible Protocol: Meticulously document the "Freeze/Vary" framework, which is the blueprint for reproducibility and versioning.
Automate Execution and Logging. Integrate your benchmarks directly into the CI/CD pipeline and leverage experiment-tracking platforms like MLflow, Weights & Biases, or Vertex AI Experiments to automate execution. These tools capture every parameter, artefact, and result, ensuring a complete, auditable record for future analysis and reproducibility.
Analyse, Decide, and Communicate. Analyse results and tie your findings directly to the original hypothesis and business objectives. Summarise with a clear, evidence-based recommendation whether to ship, refine, or abandon, explicitly referencing both your starting hypothesis and the projected business impact.
Key Takeaways
Benchmarking can be time-consuming and sometimes a bit dispiriting if the numbers aren’t what you would like. However, it is worth the investment for production systems and will help drive incremental improvement.
Treat benchmarking as a decision-making discipline to drive business impact, manage trade-offs, and de-risk deployments, not just as a metric-gathering task.
Benchmarking isn’t limited to models. It applies across the entire ML stack. Evaluate infrastructure (hardware, deployment, efficiency), models (architecture, predictive power, robustness), and data (quality, quantity, coverage, ROI) to capture a complete, actionable view of system performance.
Every benchmark should run through a disciplined loop, formulate a business-driven hypothesis, design a reproducible protocol, automate execution and logging, then analyse results to decide: ship, tweak, or kill.
Build lasting trust by measuring performance, ensuring robustness, efficiency, fairness, and compliance, and guaranteeing full reproducibility through strict versioning and automated CI/CD checks.
If you're looking for reliable public benchmarks to help evaluate your ML models, here are some excellent places to start.
For Large Language Models (LLMs), an excellent resource is TechTarget’s guide, “Benchmarking LLMs: A guide to AI model evaluation.” This can be complemented by exploring the Hugging Face Open LLM Leaderboard for regularly updated rankings of popular models.
While MLPerf, provides widely recognised standards for training and inference performance. For computer vision, benchmarks like ImageNet and COCO assess model capability, with newer benchmarks like Roboflow100-VL (robustness for vision-language models) is great for testing real-world robustness.
For tabular data, platforms like Kaggle and OpenML offer vast archives for establishing robust model baselines. Zindi complements these resources by providing fresh datasets that address specific business and societal challenges in Africa.
COMING UP… In the next article of this series, we'll explore Formal Verification of ML